So, I set out on a journey to create an API Gateway to Service integration for all 105 services listed in the API Gateway Console. After doing about 8 services I cracked the rosetta stone of API Gateway and here I'll show you how you can think about the way the services are called via their RESTful API to give a more consistent experience across services. One of the key insights from my previous post was that the aws cli somehow "knew" to add the x-amz-json-1.1 Content-Type header to the request. After doing some digging, with a lot of help from Ben K., we discovered how the cli "knew" this. This link in the botocore data directory shows where this data is loaded from.

This got me thinking about the differences between DynamoDB and Athena integration so I fired up the cli again to see how it interacts with DynamoDB
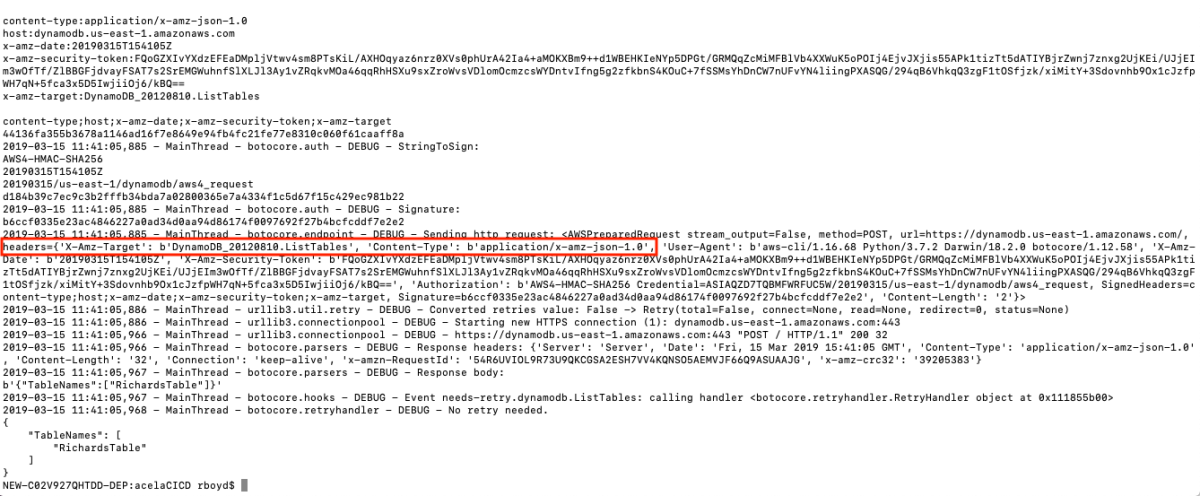
This is really interesting because the API Gateway integration uses the pattern of applying the QueryString parameter "?Action=ListTables" and doesn't include the headers. From the looks of this, we might be able to apply the same technique header-based technique to every service. This way we don't have to worry about which services support ?Actions=[....] query strings and which services don't. Let's walk through a concrete example to make this a bit easier to digest. I'm going to pick a service at random and try to duplicate this with a cloudformation template.
import glob
import random
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
sh = logging.StreamHandler()
logger.addHandler(sh)
def main():
services = glob.glob('./data/*/*/service-2.json')
logger.debug("found {} service files".format(len(services)))
print(random.choice(services))
if __name__ == "__main__":
main()
Running this gives us ...... *drumroll* .........

Cool. Let's see what we can do with Route53.
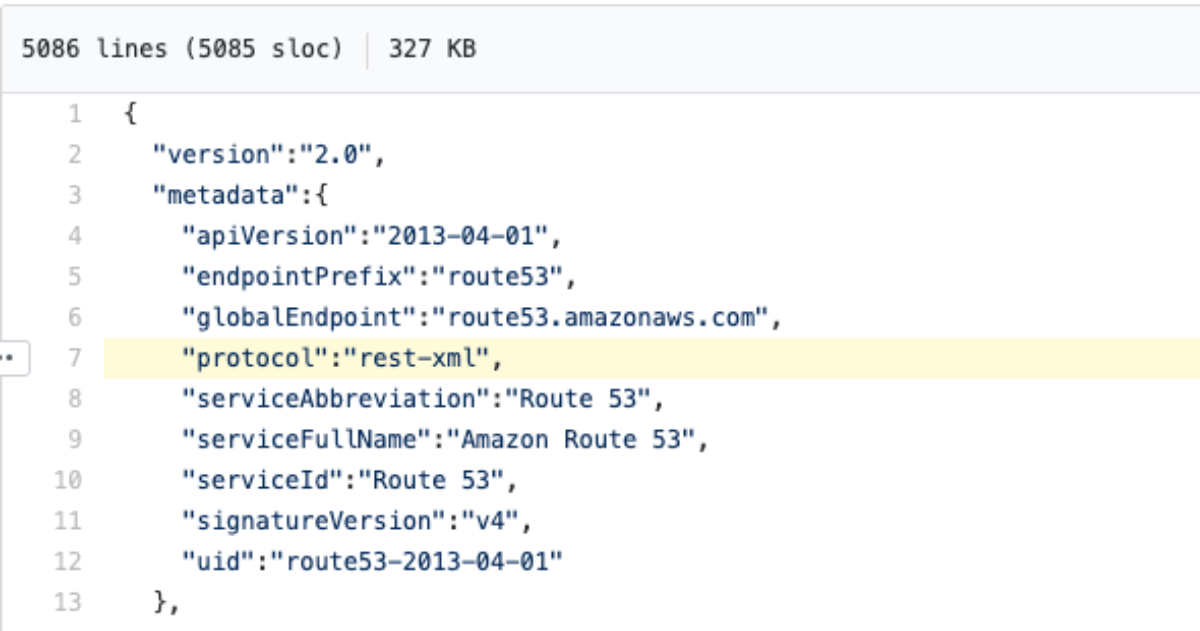
Crap. it's not using json at all. No worries though, because we're about to learn the trick. There's only about 4 protocols I've seen so far ['json', 'query', and 'rest-xml'] but I'm sure there's more hiding in there somewhere. This metadata tells us almost everything we need to know. Since there is no field called "targetPrefix" we know that we won't have to add the x-amz-target or application/x-amz-json-1.x headers. Let's try a list command with no parameters to see if we can get the connectivity working, then we'll add some parameters. Let's take a closer look at the ListHostedZones operation.
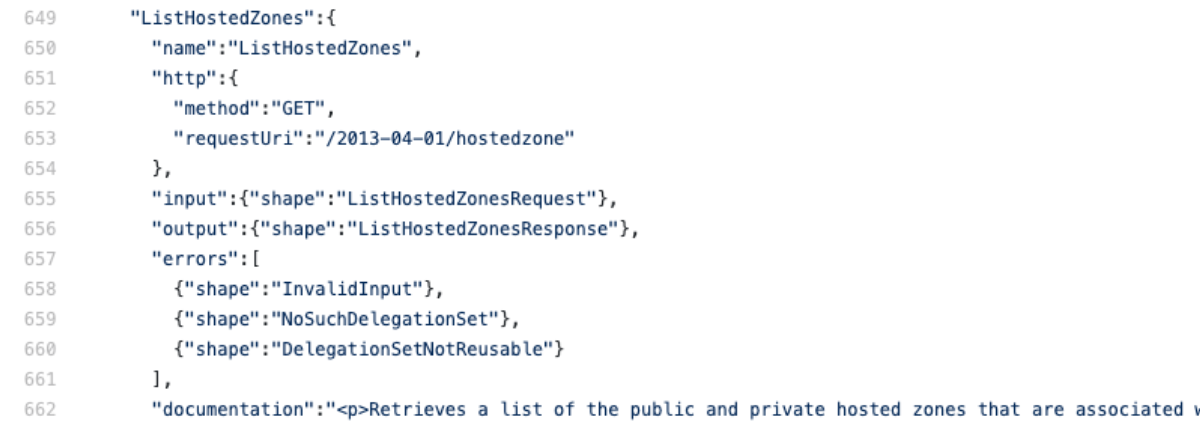
This tells us the path we want to use '/2014-04-01/hostedzone' and what HTTP method to use in the Integration Request (Note that this can be and often is different from the Method Request in API Gateway). The object also tells us what the input should look like. In this case, we're sending a get request so we don't have to worry about a request body and none of the parameters are required so we can ignore them for now. Here's the template we are going to deploy. I've bolded the parts where we deviate from a standard API Gateway service integration template.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
Route53 Integration
Resources:
Route53API:
Type: AWS::ApiGateway::RestApi
Properties:
Name: "Route53 API"
RootResource:
Type: AWS::ApiGateway::Resource
Properties:
ParentId: !GetAtt Route53API.RootResourceId
PathPart: "zones"
RestApiId: !Ref Route53API
ListHostedZonesMethod:
Type: AWS::ApiGateway::Method
DependsOn:
- RootResource
Properties:
HttpMethod: GET
ResourceId: !Ref RootResource
RestApiId: !Ref Route53API
AuthorizationType: AWS_IAM
MethodResponses:
- ResponseParameters:
method.response.header.Access-Control-Allow-Origin: true
StatusCode: 200
Integration:
Type: AWS
IntegrationHttpMethod: GET
Credentials:
Fn::GetAtt:
- AdminRole
- Arn
Uri: !Sub "arn:aws:apigateway:${AWS::Region}:route53:path/2013-04-01/hostedzone"
IntegrationResponses:
- StatusCode: 200
AdminRole:
Type: "AWS::IAM::Role"
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "apigateway.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AdministratorAccess
Let's deploy this and see what happens.
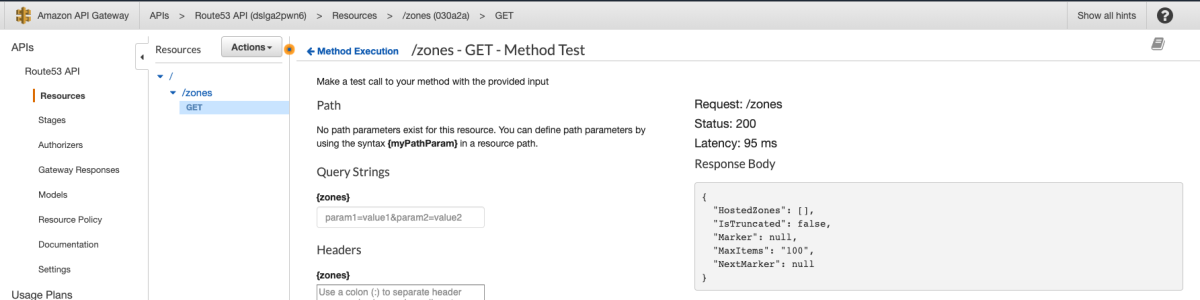
Cool, but I might be lying to you or API Gateway might be lying to you, so we should verify this by implementing some kind of mutating request so we can verify it. Since we have a ListHostedZones, let's look at the CreateHostedZone operation.

Repeating what we did last time, we need to make note of the method, requestUri, and now the input shape.

This tells us that "Name" and "CallerReference" are the only required fields (note: some services don't include a "required" field and instead add the word "Required" to the beginning of the documentation). The CallerReference is an interesting field. Its purpose is so that you can make the same request many times and be sure that the creation is idempotent, which is great if you encounter errors and want to ensure that requesting an item twice doesn't create two identical items. Here's the new API gateway Cloudformation template, with the important parts bolded. Notice that we map the application/json content-type that we expect from our clients to the text/xml that route53 expects based on the metadata["protocol"] entry in the service-2.json file linked above.
CreateHostedZonesMethod:
Type: AWS::ApiGateway::Method
DependsOn:
- RootResource
Properties:
HttpMethod: POST
ResourceId: !Ref RootResource
RestApiId: !Ref Route53API
AuthorizationType: AWS_IAM
MethodResponses:
- ResponseParameters:
method.response.header.Access-Control-Allow-Origin: true
StatusCode: 200
Integration:
Type: AWS
IntegrationHttpMethod: POST
RequestParameters:
integration.request.header.Content-Type: "'text/xml'"
Credentials:
Fn::GetAtt:
- AdminRole
- Arn
Uri: !Sub "arn:aws:apigateway:${AWS::Region}:route53:path/2013-04-01/hostedzone"
RequestTemplates:
application/json: |
<CreateHostedZoneRequest xmlns="https://route53.amazonaws.com/doc/2013-04-01/">
<Name>$input.params('zoneName').</Name>
<CallerReference>$input.params('user-provided-request-id')</CallerReference>
</CreateHostedZoneRequest>
IntegrationResponses:
- StatusCode: 200
We see that this takes the "zoneName" and "user-provided-request-id" querystring parameters and maps them into the xml of the request. Sending this request with the querystring "zoneName=RichardBoydIsCool.com&user-provided-request-id=19640112" looks like a success

Awesome. Now let's try the "ListHostedZones" that we created earlier and make sure our new HostedZone shows up.
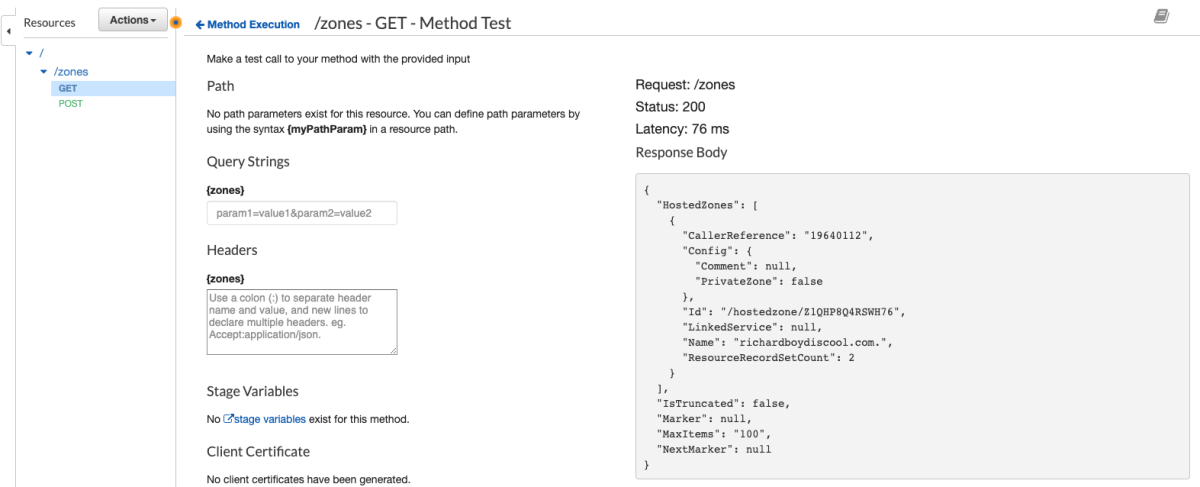
Great!!!! Now we know how to integrate with any service that API Gateway advertises. Stay tuned next week for another post that will make this even easier ;)