Today, the AWS Cloud Development Kit team released experimental support for Python in the CDK. While it's still an experimental release and there are some rough edges, it's a big step forward and I wanted to give it a test drive. The biggest pain-point so far is that "pip install aws-cdk.cdk" only installs the shims that connect the CDK (which is written in TypeScript) to Python language bindings. Users will have to make sure that they have NodeJS (>= 8.11.x) installed and perform "npm install cdk" to install the actual cdk goodies. Once that's out fo the way, we're all set to start declaring our infrastructure. We're going to create a Lambda function that just echoes "Hello, world!".
I've created a new python project in PyCharm.

Now, let's define our requirements in a requirements.txt file.
aws-cdk.aws-lambda aws-cdk.cdk
Next we create our lambda code. We're going to name this file lambda-handler.py
def main(event, context):
print("Hello, world!")

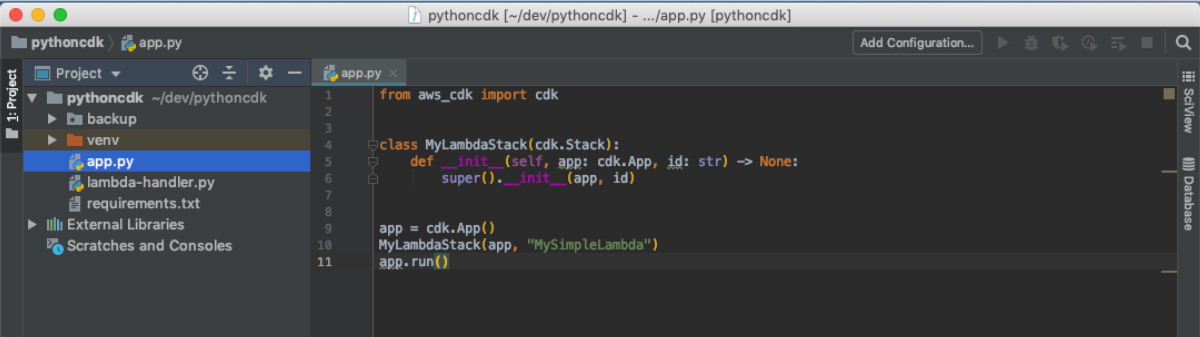
So far, this has all been the same development process we follow for developing any lambda function, but here is where we start to leverage CDK. Instead of the SAM approach where we would have a cloudformation template that we either have to craft or copy from a previous project, CDK let's us declare our infrastructure with all the goodness that modern IDEs provide (type-checking, tab completion, syntax highlighting, etc...). Let's create a file call app.py that will contain the logic for building our application.
from aws_cdk import cdk
class MyLambdaStack(cdk.Stack):
def __init__(self, app: cdk.App, id: str) -> None:
super().__init__(app, id)
app = cdk.App()
MyLambdaStack(app, "MySimpleLambda")
app.run()
Next we need a file called cdk.json, this file tells CDK how to run the application that builds our infrastructure, the CDK application captures the applications we define here and uses them to generate the cloudformation needed to build this application in AWS.
{
"app": "python3 app.py"
}
Now we're ready to hop over to the console and build our app. From the root of your package run "cdk synthesize" to see the synthesized cloudformation YAML.
cdk synthesize

Well, that was pretty anti-climactic. there's nothing there but some metadata. Let's go back to our app and add our lambda function code.
First, we're going to read in the contents of lambda-handler.py so that we can pass the raw string to our Lambda Function. This is the same way that you define inline code in a raw cloudformation lambda function.
with open("lambda-handler.py", encoding="utf8") as fp:
handler_code = fp.read()
Now that we have our lambda code, let's use it to build a Function.
lambdaFn = lambda_.Function(
self,
"Singleton",
code=lambda_.InlineCode(handler_code),
handler="index.main",
timeout=300,
runtime=lambda_.Runtime.PYTHON37,
)
Now we can jump back to our console and synthesize this again
cdk synthesize
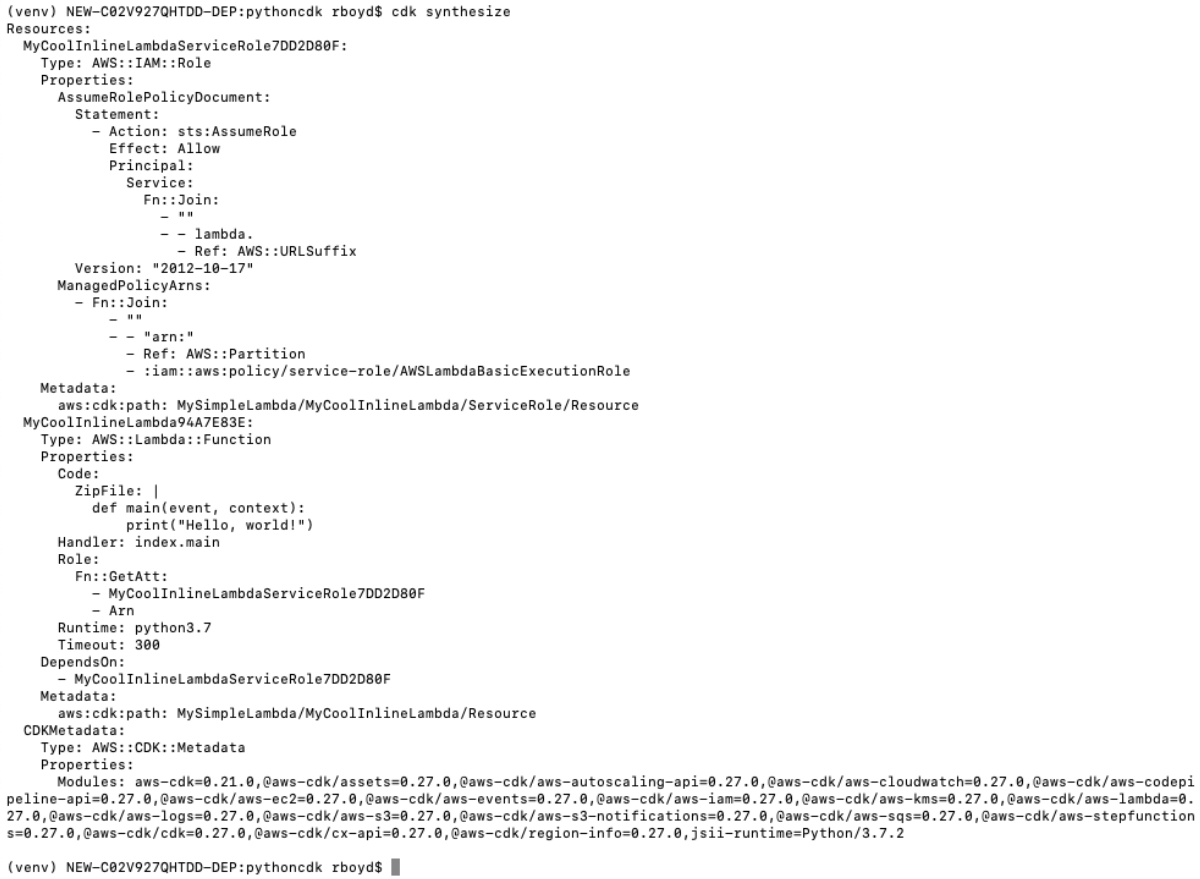
Great!!! I have YAML in the console, exactly where I need it ;) . but how do I do anything with this? CDK has solved that for us too.
cdk deploy --profile workshop
"--profile workshop" is just an aws config profile I use for demos, if you have previously run aws configure You won't need to supply that argument.

Let's hop over to the AWS Console and see what's good.
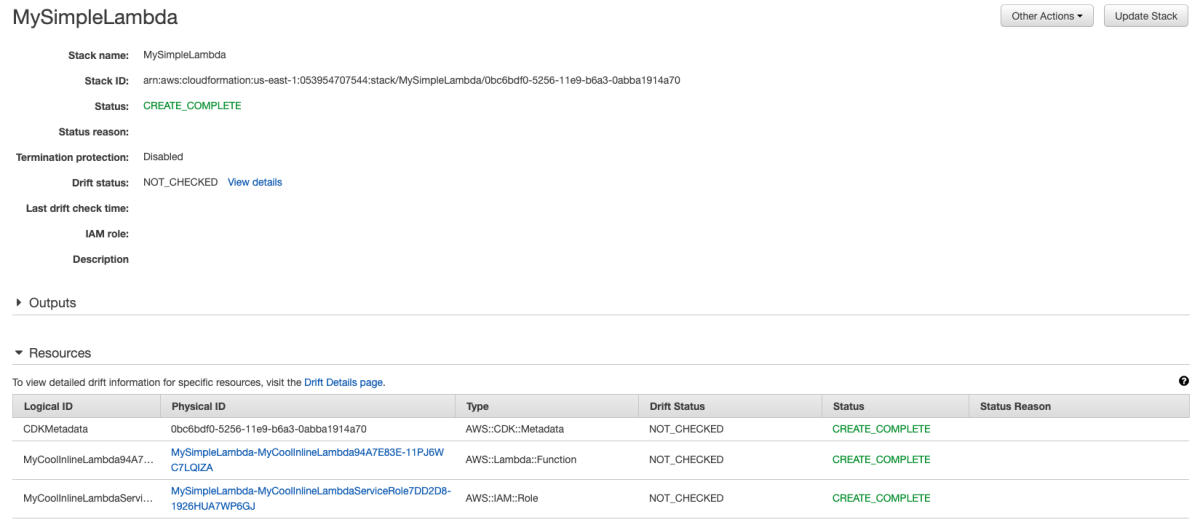
Awesome. Let's go see this Lambda in action.
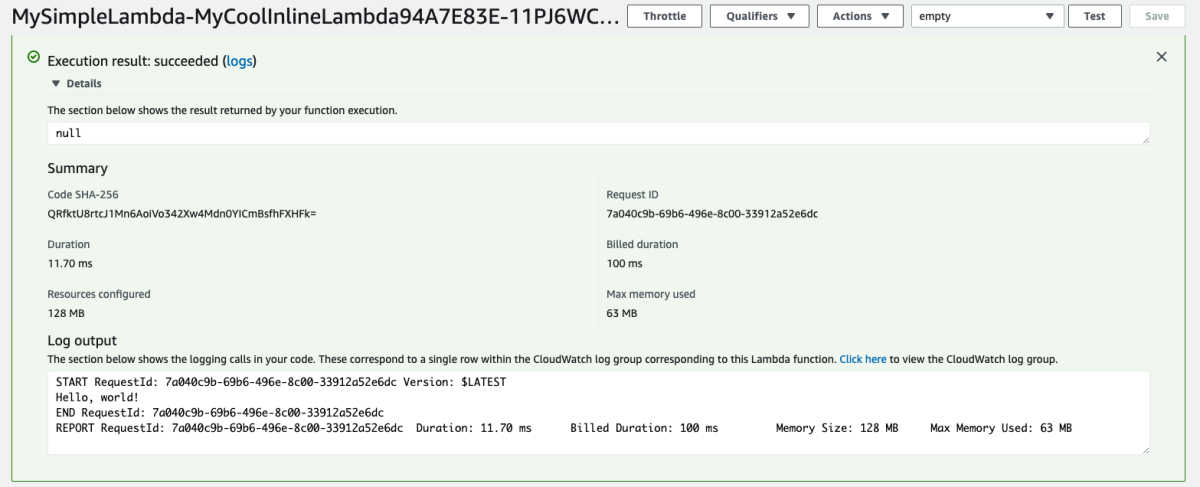
WOOT!! WOOT!! Now we're building infrastructure in a language that's more fun to work with than YAML/JSON and it handles much of the boilerplate Cloudformation that I don't want to think about.